
Hibernate Formula 动态查询的原理和缺点
功能需求
配送单管理页面中,“派工需求时间”和“分批时间”是多对一的关系,即多个“派工需求时间”会对应一个“分批时间”,项目需要展示一个“分批时间”对应的多个“派工需求时间”中最小的那个。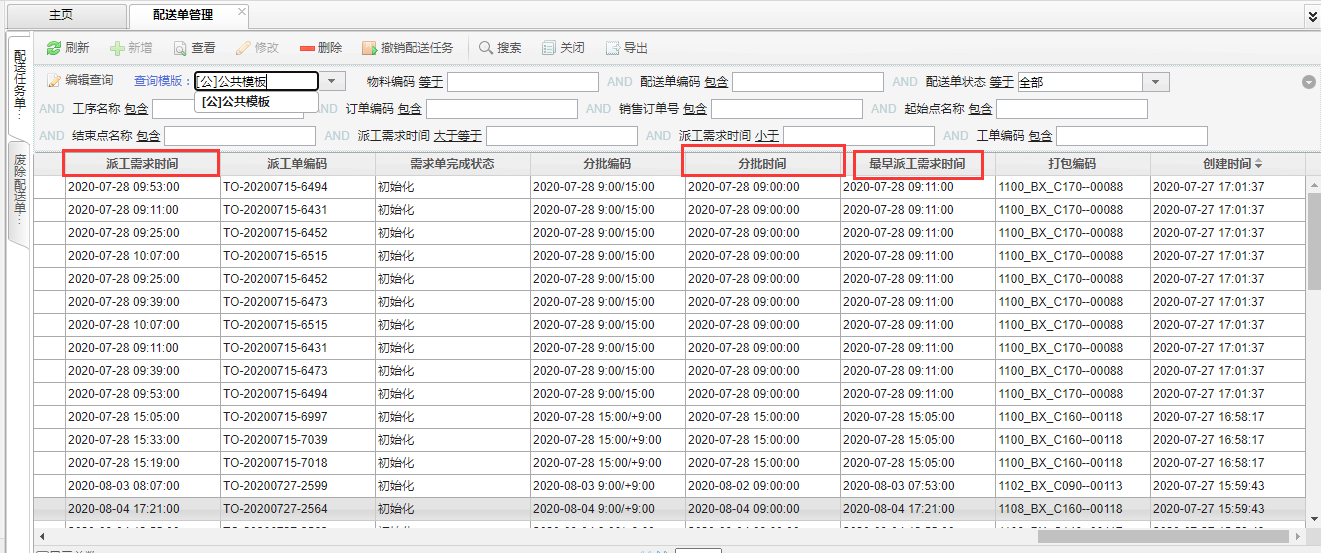
功能实现
由于页面查询使用的产品标准查询,即实体查询的模式,实体上增加对应的字段即可,而改字段的值通过一个子查询实现即可。这与 Hibernate 的虚拟列 Formula 查询场景是一致的。代码实现如下:
@Formula("(select MIN(req.TRACK_SCHEDULE_TIME) " +
" from UMM_TRANSFER_PROREQUIREMENTS req " +
" where req.IS_ACTIVE = 0 " +
" and req.IS_DELETE = 0 " +
" and req.DIS_BILL_GID = DIS_BILL_GID)")
public String getTransferTime2()
{
return transferTime2;
}
实体增加字段后,jsp 页面添加对应的字段即可,其它的内容不需要修改。
遇到的问题
该查询在测试库查询没有问题,但是部署到正式服务后却发现页面查询很慢。数据量在 10W 左右,查询时间在 3 分钟,增加对应字段的索引后,查询仍在 10 秒左右。
进一步分析
通过日志录制,抓取到该虚拟列的查询经过 Hibernate 的解析,最终转化为投影子查询
select *
from (select this_.gid as y0_,
this_.work_center_code as y1_,
this_.work_center_name as y2_,
disbill1_.bill_id as y3_,
disbill1_.state as y4_,
this_.p_req_code as y5_,
this_.op_code as y6_,
this_.op_name as y7_,
this_.mrl_code as y8_,
this_.mrl_name as y9_,
this_.work_cell_code as y10_,
this_.work_cell_name as y11_,
this_.create_req_time as y12_,
this_.schedule_time as y13_,
workorder2_.gid as y14_,
workorder2_.code as y15_,
order3_.sales_of_bound_code as y16_,
order3_.code as y17_,
this_.work_order_qty as y18_,
this_.mrl_qty as y19_,
this_.mrl_single_qty as y20_,
this_.mrl_complete_qty as y21_,
this_.s_node_type as y22_,
this_.s_node_code as y23_,
this_.s_node_name as y24_,
this_.location_code as y25_,
this_.location_name as y26_,
this_.e_node_type as y27_,
this_.e_node_code as y28_,
this_.e_node_name as y29_,
this_.last_e_node_code as y30_,
this_.supp_code as y31_,
this_.supp_name as y32_,
this_.tran_init_time as y33_,
this_.tran_time as y34_,
this_.tran_warning_time as y35_,
this_.track_schedule_time as y36_,
this_.track_code as y37_,
this_.state as y38_,
this_.num_batch as y39_,
this_.num_type as y40_,
this_.transfer_time as y41_,
(select MIN(req.TRACK_SCHEDULE_TIME)
from UMM_TRANSFER_PROREQUIREMENTS req
where req.IS_ACTIVE = 0
and req.IS_DELETE = 0
and req.DIS_BILL_GID = this_.DIS_BILL_GID) as y42_,
this_.warp_code as y43_,
this_.create_date as y44_,
this_.going_to as y45_
from umm_transfer_prorequirements this_
left outer join umm_dis_bill disbill1_
on this_.dis_bill_gid = disbill1_.gid
left outer join umpp_work_order workorder2_
on this_.work_order_gid = workorder2_.gid
left outer join umpp_plan_order order3_
on workorder2_.order_gid = order3_.gid
where (this_.p_req_type = 2 and this_.is_delete <> 1)
order by y44_ desc)
where rownum <= 20
经测试,去掉其中的 select MIN()的字段后,查询可以在 1 秒内完成,由此知道查询的慢是由于子查询效率低导致的 (oracle 和 mysql 都有这个问题,原因是需要建临时表,开销比较大)。
解决办法就是使用关联查询,效率会远高于子查询,对应 SQL 如下:
select THIS_.GID as Y0_,
THIS_.WORK_CENTER_CODE as Y1_,
THIS_.WORK_CENTER_NAME as Y2_,
DISBILL1_.BILL_ID as Y3_,
DISBILL1_.STATE as Y4_,
THIS_.P_REQ_CODE as Y5_,
THIS_.OP_CODE as Y6_,
THIS_.OP_NAME as Y7_,
THIS_.MRL_CODE as Y8_,
THIS_.MRL_NAME as Y9_,
THIS_.WORK_CELL_CODE as Y10_,
THIS_.WORK_CELL_NAME as Y11_,
THIS_.CREATE_REQ_TIME as Y12_,
THIS_.SCHEDULE_TIME as Y13_,
WORKORDER2_.GID as Y14_,
WORKORDER2_.CODE as Y15_,
ORDER3_.SALES_OF_BOUND_CODE as Y16_,
ORDER3_.CODE as Y17_,
THIS_.WORK_ORDER_QTY as Y18_,
THIS_.MRL_QTY as Y19_,
THIS_.MRL_SINGLE_QTY as Y20_,
THIS_.MRL_COMPLETE_QTY as Y21_,
THIS_.S_NODE_TYPE as Y22_,
THIS_.S_NODE_CODE as Y23_,
THIS_.S_NODE_NAME as Y24_,
THIS_.LOCATION_CODE as Y25_,
THIS_.LOCATION_NAME as Y26_,
THIS_.E_NODE_TYPE as Y27_,
THIS_.E_NODE_CODE as Y28_,
THIS_.E_NODE_NAME as Y29_,
THIS_.LAST_E_NODE_CODE as Y30_,
THIS_.SUPP_CODE as Y31_,
THIS_.SUPP_NAME as Y32_,
THIS_.TRAN_INIT_TIME as Y33_,
THIS_.TRAN_TIME as Y34_,
THIS_.TRAN_WARNING_TIME as Y35_,
THIS_.TRACK_SCHEDULE_TIME as Y36_,
THIS_.TRACK_CODE as Y37_,
THIS_.STATE as Y38_,
THIS_.NUM_BATCH as Y39_,
THIS_.NUM_TYPE as Y40_,
THIS_.TRANSFER_TIME as Y41_,
t.min_TRACK_SCHEDULE_TIME as Y42_,
THIS_.WARP_CODE as Y43_,
THIS_.CREATE_DATE as Y44_,
THIS_.GOING_TO as Y45_
from UMM_TRANSFER_PROREQUIREMENTS THIS_
left outer join UMM_DIS_BILL DISBILL1_
on THIS_.DIS_BILL_GID = DISBILL1_.GID
left outer join UMPP_WORK_ORDER WORKORDER2_
on THIS_.WORK_ORDER_GID = WORKORDER2_.GID
left outer join UMPP_PLAN_ORDER ORDER3_
on WORKORDER2_.ORDER_GID = ORDER3_.GID
LEFT JOIN (
select min(REQ.TRACK_SCHEDULE_TIME) as min_TRACK_SCHEDULE_TIME,DIS_BILL_GID
from UMM_TRANSFER_PROREQUIREMENTS REQ
where REQ.IS_ACTIVE = 0
and REQ.IS_DELETE = 0 group by DIS_BILL_GID
) t on t.DIS_BILL_GID=THIS_.DIS_BILL_GID
where (THIS_.P_REQ_TYPE = 2 and THIS_.IS_DELETE <> 1)
order by Y44_ desc
问题解决
从 SQL 上解决了查询的效率问题,怎么转化代码实现呢?关联查询再 Hibernate 中体现为实体关联,则需要增加一个实体,然后关联到原实体中。新增的实体,可以先在数据库建视图,然后实体直接关联视图,也可以直接使用 Hibernate 的 subselect 通过 sql 实现。现采用第一种方式。
数据库视图:
create or replace view UMM_TRANSFER_REQ_VIEW as
SELECT DIS_BILL_GID AS GID, MIN(REQ.TRACK_SCHEDULE_TIME) as TRACK_SCHEDULE_TIME
from UMM_TRANSFER_PROREQUIREMENTS REQ
where REQ.IS_ACTIVE = 0 and REQ.IS_DELETE = 0
group by DIS_BILL_GID
新增实体:
@Entity
@Table(name = "UMM_TRANSFER_REQ_VIEW")
@Immutable
public class UmmTransferReqView
实体关联
@ManyToOne(fetch=FetchType.LAZY,targetEntity=UmmTransferReqView.class)
@JoinColumn(name="DIS_BILL_GID", insertable=false, updatable=false)
public UmmTransferReqView getReqView()
{
return reqView;
}