
消息引擎与规则引擎培训文档 2
kafka 配置优化及消息引擎应用
0. 背景:
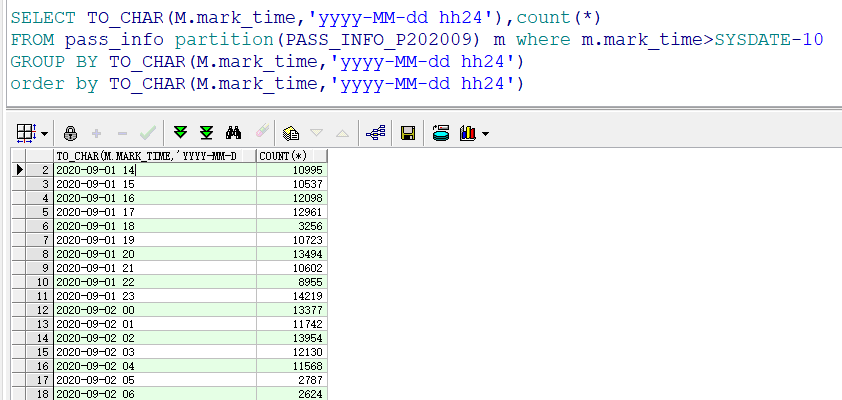
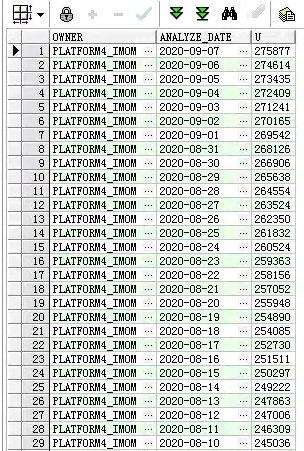
锡柴全自动化产线,数采过点每小时 1w 条左右,加上其他设备,刀具等高频率的采集数据,数据库每天增加 1.2~1.5G 左右
kafka-producer-perf-test 参数说明:
1. messages 生产者发送走的消息数量
2. message-size 每条消息的大小
3. batch-size 每次批量发送消息的数量
4. topics 生产者发送的
5. topic threads 生产者
6. broker-list 安装 kafka 服务的机器 ip:port 列表
7. producer-num-retries 一个消息失败发送重试次数
8. request-timeouts-ms 一个消息请求发送超时时间
kafka-consumer-perf-test 参数说明:
zookeeper zk 配置
1. messages 消费者消费消息的总数量
2. topic 消费者需要消费的 topic
3. threads 消费者使用几个线程同时消费
4. group 消费者组名称
5. socket-buffer-sizes socket 缓存大小
6. fetch-size 每次想 kafka broker 请求消费消息大小
7. consumer.timeout.ms 消费者去 kafka broker 拿一条消息的超时时间
kafka-producer-perf-test --topic ppp --num-records 500000 --record-size 2000 --throughput -1 --producer-props bootstrap.servers=localhost:9092 acks=1

kafka-consumer-perf-test --message-size 2000 --messages 500000 --batch-size 10 --topic ppp --partitions 1 --threads 1 --zookeeper localhost:2181

生产者参数
org.apache.kafka.clients.producer.ProducerConfig
- thread: 我们测试时的单机线程数;
- bath-size: 我们所处理的数据批次大小;
- ack: 主从同步策略在生产消息时特别需要注意,是 follower 收到后返回还是只是 leader 收到后返回;
- message-size: 单条消息的大小,要在 producer 和 broker 中设置一个阈值,且它的大小范围对吞吐量也有影响;
- compression-codec: 压缩方式,目前有不压缩,gzip,snappy,lz4 四种方式;
- partition: 分区数,主要是和线程复合来测试;
- replication: 副本数;
- througout: 我们所需要的吞吐量,单位时间内处理消息的数量,可能对我们处理消息的延迟有影响;
- linger.ms:两次发送时间间隔,满足后刷一次数据。
消费者参数
org.apache.kafka.clients.consumer.ConsumerConfig
- session.timeout.ms 设置了超时时间,表示 consumer 向 broker 发送心跳的超时时间
- heartbeat.interval.ms 表示 consumer 每次向 broker 发送心跳的时间间隔,一般来说,session.timeout.ms 的值是 heartbeat.interval.ms 值的 3 倍以上。
- max.poll.interval.ms 每次消费的处理时间,表示 consumer 每两次 poll 消息的时间间隔。简单地说,其实就是 consumer 每次消费消息的时长。如果消息处理的逻辑很重,那么市场就要相应延长。否则如果时间到了 consumer 还么消费完,broker 会默认认为 consumer 死了,发起 rebalance。
- max.poll.records 每次消费的消息数,表示每次消费的时候,获取多少条消息。获取的消息条数越多,需要处理的时间越长。所以每次拉取的消息数不能太多,需要保证在 max.poll.interval.ms 设置的时间内能消费完,否则会发生 rebalance。
- thread:我们测试时的单机线程数;
-
fetch-size:抓取数据量;
- partition: 分区数,主要是和线程复合来测试;
- replication: 副本数;
- througout: 我们所需要的吞吐量,单位时间内处理消息的数量,可能对我们处理消息的延迟有影响;
Broker 相关参数
- num.replica.fetchers:副本抓取的相应参数,如果发生 ISR 频繁进出的情况或 follower 无法追上 leader 的情况则适当增加该值,== 但通常不要超过 CPU 核数 +1;==
- num.io.threads:broker 处理磁盘 IO 的线程数,主要进行磁盘 io 操作,高峰期可能有些 io 等待,因此配置需要大些。== 建议配置线程数量为 cpu 核数 2 倍,最大不超过 3 倍;==
- num.network.threads:broker 处理消息的最大线程数,和我们生产消费的 thread 很类似主要处理网络 io,读写缓冲区数据,基本没有 io 等待,== 建议配置线程数量为 cpu 核数加 1;==
- log.flush.interval.messages:每当 producer 写入多少条消息时,刷数据到磁盘;
- log.flush.interval.ms:每隔多长时间,刷数据到磁盘;
1. kafka 配置优化
java 中操作 kafka 可以通过 kafka-client 或者使用 spring-kafka 来实现,平台采用的实现方式是 kafka-client
A. 解决测试问题
大家连着一个库,不知道消息被谁发了?

B. 解决部署问题
双机集群环境下
通过 producerAutoStartup 的属性设置,一台机器进行发送,避免了频繁的锁竞争。
单机集群环境下
两个节点用一份配置文件,还没有尝试通过 spEL 配置 server 属性来。
优点:
解决了锁竞争的问题,一个节点发送消息也能满足系统使用,(平台可以验证下分布式锁到底能否生效)
IRedisProxy redis = SpringContextHolder.getBean("shardedRedisProxyService");
String key = "s1";
String value = "s1";
int seconds = 60 * 1000;
for (int i = 0; i < 100; i++) {
Thread t = new Thread(() -> {
if (redis.exists(key))
{
System.out.println("lock success: " + Thread.currentThread().getName());
} else {
redis.setnx(key, value);
redis.expire(key, seconds);
System.out.println("lock failed: " + Thread.currentThread().getName());
}
});
t.start();
}
缺点:
带来单点问题,如果发送节点挂掉,消息发不出去,可以考虑通过 zk 的监听机制,谁先上线启动谁的 producer route,如果挂掉的话启动另一个节点的 route
C. 解决存储问题
MBR_MSG_RECORD+MBR_MSG_STATE 作分区存储,BLOB 字段存单独的表空间,建议还是通过数据库的 JOB 定时创建分区,系统自动创建分区带来一时的方便,但在后期表分区的维护上很大麻烦,只能通过代码去解决。
D. 解决发送问题
producer 的问题 (平台需要修改)
-
显示关闭
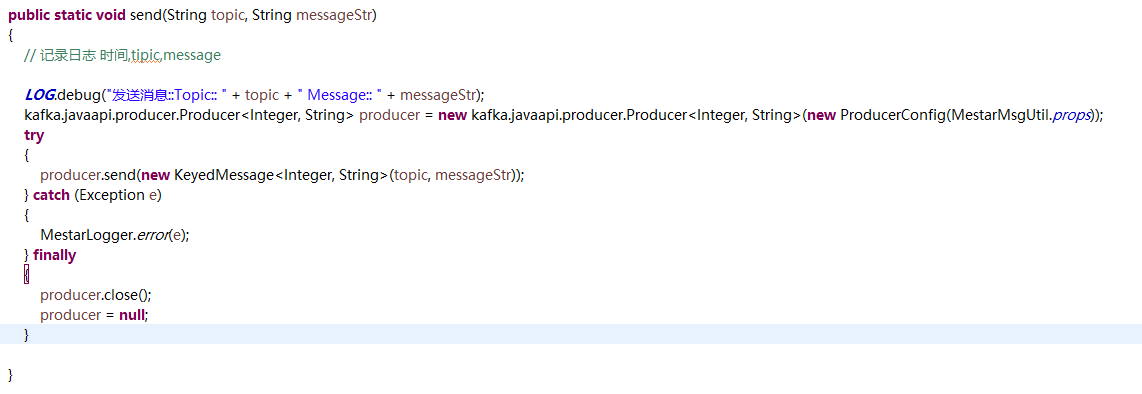
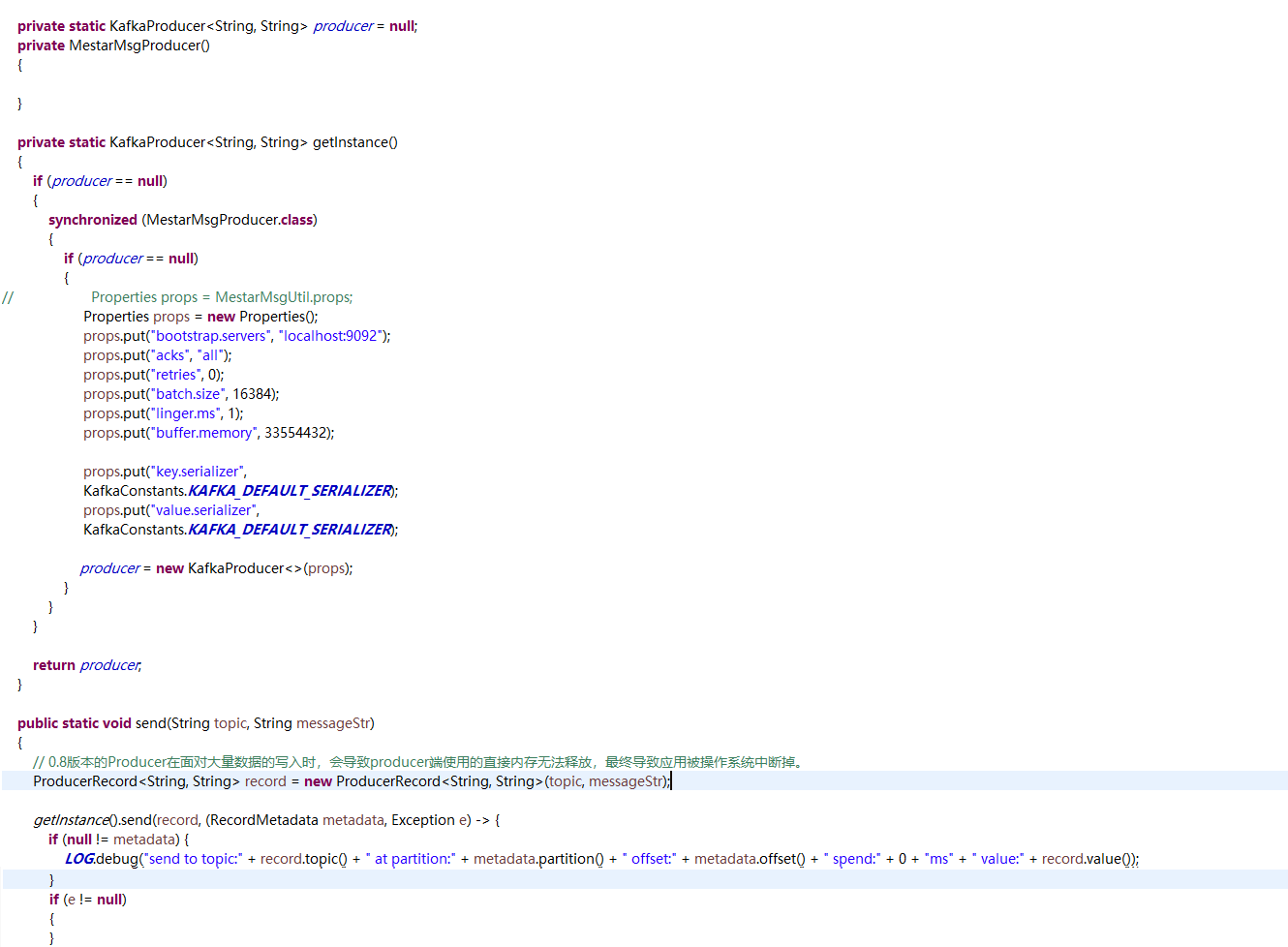
-
用单例方法
They are simply old vs new APIs. Kafka starting 0.8.2.x exposed a new set of API’s to work with kafka, older being Producer which works with KeyedMessage[K,V] where the new API is KafkaProducer with ProducerRecord[K,V]:
As of the 0.8.2 release we encourage all new development to use the new Java producer. This client is production tested and generally both faster and more fully featured than the previous Scala client.
// 0.8 版本的 Producer 在面对大量数据的写入时,会导致 producer 端使用的直接内存无法释放,最终导致应用被操作系统中断掉。
2. 消息引擎应用
[文档:消息引擎与规则引擎培训文档 1.note 链接:http://note.youdao.com/noteshare?id=2d2c287d1f1d0027bee9c1df670df4df]( 文档:消息引擎与规则引擎培训文档 1.note 链接:http://note.youdao.com/noteshare?id=2d2c287d1f1d0027bee9c1df670df4df)
3. 常见问题解决
[文档:Zookeeper 与 Kafka 问题.note 链接:http://note.youdao.com/noteshare?id=611792ca5ff58f253a6d73fb99d8d037]( 文档:Zookeeper 与 Kafka 问题.note 链接:http://note.youdao.com/noteshare?id=611792ca5ff58f253a6d73fb99d8d037&sub=96EE38854DBD45A5B827E6126E7AB329)
4. Groovy 测试脚本
import java.util.ArrayList;
import java.util.Date;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import com.epichust.mestar.utils.spring.SpringContextHolder;
import com.epichust.mestar.rule.service.RuleService;
RuleService ruleSvc = SpringContextHolder.getBean("ruleService");
Map<String, Object> context = new HashMap<>();
context.put("sum", "");
String cmd ='''
是否空字符串('')?"aa":"bb";
getSqlVal('select sysdate from dual',[])
'''
Object ret = ruleSvc.executeRule(cmd, context);
return ret;
import java.util.ArrayList;
import java.util.Date;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import com.epichust.dao.unimax.BppCommonDao;
import com.epichust.mestar.rule.entity.MbrMsgRecord;
import com.epichust.mestar.utils.web.JSONUtil;
import com.epichust.mestar.utils.spring.SpringContextHolder;
import com.epichust.mestar.rule.service.RuleService;
BppCommonDao dao = SpringContextHolder.getBean("bppCommonDao");
MbrMsgRecord message = dao.get(MbrMsgRecord.class, "402893817376a596017376c768b9004c");
RuleService ruleSvc = SpringContextHolder.getBean("ruleService");
Object entity = JSONUtil.readJSON2Bean(message.getContent(), Class.forName(message.getBeanName()));
Map<String, Object> context = new HashMap<>();
context.put("obj", entity);
context.put("tag", Class.forName("com.epichust.to.unimax.UqcmChkBillTO").newInstance());
String cmd ='''
tag.mrlName=obj.mrlName;tag.workCenterId=obj.workCenterId;tag.opCode=obj.opCode;tag.opId=obj.opId;tag.planOrderCode=obj.planOrderCode;tag.workCenterCode=obj.workCenterCode;tag.workCellCode=obj.workCellCode;tag.workCellName=obj.workCellName;tag.chkBillTypeId=obj.chkBillTypeId;tag.chkTypeCode=obj.chkTypeCode;tag.mrlCode=obj.mrlCode;tag.workCenterName=obj.workCenterName;tag.opName=obj.opName;tag.type=obj.type;tag.uexDaqInfoId=obj.uexDaqInfoId;tag.workCellId=obj.workCellId;
prjTargetTrans.insertZJRK(tag);
return tag.workCenterId;
'''
Object ret = ruleSvc.executeRule(cmd, context);
return ret;